روابط عمومی شرکت ایدکو (توزیع کننده محصولات کسپرسکی در ایران)؛ به طور حتم آینده از امروز بهتر خواهد بود؛ اما این روزها فناوری هوش مصنوعی (AI) سؤالات زیادی را در ذهن ایجاد میکند که خیلی از این سؤالات، اصول اخلاقی را نشانه رفتهاند. صرف نظر از پیشرفت تکنولوژی در آینده، تا همین جای کار، فناوری یادگیری ماشین[1] تا چه حد ما را شگفتزده و غافلگیر کرده است؟ آیا میتوان ماشین را فریب داد؟ و اگر بشود به نظر شما فریب دادنش تا چه اندازه سخت خواهد بود؟ آیا همهی اینها نهایتاً به اسکاینت (نابودگر) و یا شورش ماشینها ختم نخواهد شد؟ بیایید نگاهی به ماجرا بیاندازیم.
هوش مصنوعی قوی و ضعیف
ابتدا باید بین دو مفهوم تفاوت قائل شویم: هوش مصنوعی قوی و هوش مصنوعی ضعیف. هوش مصنوعی قوی، ماشینی فرضی است که قادر به تفکر بوده و کاملاً از وجود و حضور خود آگاه است. این هوش مصنوعی نه تنها میتواند کارهای سخت را انجام دهد، بلکه همچنین چیزهایی جدید را نیز میآموزد.
هوش مصنوعی ضعیف را هماکنون داریم. آن را میتوان در کارکردهایی که به منظور حل مشکلات خاص طراحی شدهاند یافت: مانند شناسایی تصویر، رانندگی خودرو، بازی کردن گیم گو[2] و غیره. هوش مصنوعی ضعیف چیزی است که ما بدان «یادگیری ماشین» میگوییم.
هنوز نمیدانیم آیا میشود هوش مصنوعی قوی را اختراع کرد یا خیر. بر اساس پژوهشهای یک متخصص، باید 45 سال دیگر صبر کرد تا شاهد چنین پدیدهای بود. این یعنی "روزی از این روزها".برای مثال، همچنین متخصصان میگویند قدرت همجوشی[3] تا 40 سال دیگر تجاری خواهد شد- چیزی که 50 سال پیش گفته میشد.
اِشکالِ کار کجاست؟
هنوز کسی مطمئن نیست هوش مصنوعی قوی میتواند ساخته شود یا نه؛ اما مدتی است که هوش مصنوعی ضعیف را در بسیاری از حوزهها تجربه میکنیم. تعداد این حوزهها هر سال در حال افزایش است. یادگیری ماشین به ما این اجازه را میدهد تا از عهدهی انجام برخی کارهای اجرایی بدون برنامهریزیِ شفاف برآییم؛ این فناوری، خود از روی نمونهها یاد میگیرد.
ما به ماشینها میآموزیم که برخی مشکلات خاص و تعیینشده را حل کنند؛ بنابراین مدل ریاضی نهایی -چیزی که بدان الگوریتم "یادگیری" میگوییم- نمیتواند به طور ناگهانی به برده کردن و یا نجاتِ بشر تمایل پیدا کند. به بیانی دیگر، نباید از اسکاینت ناشی از هوش مصنوعی ضعیف بترسیم؛ اما بالاخره نمیشود اطمینان کامل هم بدان داشت. احتمالاً این گوشه و کنار چالشهایی نیز در کمیناند:
- نیاتِ شر
اگر به ارتشی از پهپادها بیاموزیم که با استفاده از یادگیری ماشین، ادمها را بکشند، آیا این انسانی و اخلاقی است؟
سال گذشته سر همین موضوع رسوایی به بار آمد. گوگل در حال ساخت نرمافزاری بود مخصوص مقاصد نظامی که Project Maven نام داشت و پهپادها را نیز شامل میشد. در آینده، این پروژه میتوانست به ساخت سامانههای تسلیحاتی مستقل (خودکار) کمک کند. در نتیجه، 12 نفر از کارکنان گوگل به نشان اعتراض این شرکت را ترک کرده و 4000 کارمند دیگر دادخواستی دادند مبنی بر اینکه گوگل قرارداد خود را با ارتش فسخ کند. بیش از 1000 دانشمند سرشناس حوزهی هوش مصنوعی، اخلاقیات و آیتی نیز نامهای سرگشاده به گوگل نوشتند و از این کمپانی خواستند تا این پروژه را رها کرده و از توافق بینالمللی بر سر منع تسلیحات مستقل حمایت کند.
- تعصب برنامهنویس
حتی اگر توسعهدهندگان الگوریتم یادگیری ماشین نیت شری نداشته باشند، باز هم خیلی از آنها از خیر پول نمیگذرند. یعنی الگوریتمهایی که مینویسند قرار است برایشان راهی برای درآمدزایی باشد. حال این درآمدزایی میتواند هم به نفع بشر باشد و هم به ضرر. برخی از الگوریتمهای پزشکی این طور طراحی شدهاند که به جای دورههای درمانی کمهزینهتر، درمانهای گران را برای بیماران پیشنهاد میدهند.
برخی اوقات خودِ جامعه هم دوست ندارد یک الگوریتم به معیار اخلاق و انسانیت بدل شود. برای مثال، سرعت ترافیک و نرخ مرگ بر اثر تصادفات: میتوان به خودروهای خودگردان برنامه داد تا بیشتر از 15 مایل بر ساعت نرانند؛ این میتواند تصادفات منجر به مرگ را تا حد صفر کاهش دهد اما از طرفی این امر میتواند مزایای استفاده از خودرو را نفی کند.
- پارامترهای سیستم همیشه هم مرتبط با مسائل اخلاقی نیستند
کامپیوترها به طور پیشفرض هیچ چیز از اخلاقیات نمیدانند. یک الگوریتم میتواند با هدف بالا بردن سطح تولید ناخالص ملی/سودمندی نیروی کار/امید به زندگی، بودجهای ملی جمع کند؛ اما بدون محدودیتهای اخلاقی که در مدل برنامهنویسیشده است، این امر میتواند منجر به حذف بودجهی مدارس، آسایشگاهها و محیطزیست شود چراکه آنها مستقیماً تولید ناخالص ملی را افزایش نمیدهند.
- نسبی بودن مفهوم اخلاق
اخلاقیات به مرور زمان دستخوش تغییر میشود و برخی اوقات این تغییر خیلی سریع انجام میگیرد. برای مثال، عقایدِ افراد در مورد مسائلی چون حقوق LGBT[4] یا ازدواجهایی با نژادهای مختلف/بین قبیلهای در طول یک نسل به طور قابل ملاحظهای تغییر کرده است. اصول اخلاقی همچنین میتواند بین گروههای یک کشور نیز متغیر باشد (فرقی ندارد کدام کشور). برای مثال در چین استفاده از قابلیت شناسایی چهره برای بازرسی عمومی در سطح گسترده تبدیل به عُرف و هنجار شده است. دیگر کشورها شاید این را بد بدانند؛ بنابراین اتخاذ چنین تصمیمی بنا به شرایط و هنجارهای هر کشور متغیر است.

موقعیت سیاسی نیز اهمیت بسیاری دارد. برای مثال جنگ تروریستی به طور چشمگیری -و با سرعت بسیار بالایی- برخی آرمانها و ارزشهای اخلاقی را در بسیاری از کشورها دچار تحول کرده است.
- یادگیری ماشین انسانها را عوض میکند
سیستمهای یادگیری ماشین-تنها نمونهای از هوش مصنوعی که مستقیماً مردم را تحتالشعاع قرار میدهد- بر اساس امتیازدهیهای شما به فیلمها، فیلمهای جدید را پیشنهاد داده و سپس سلایق شما را با سلایق کاربران دیگر نیز مقایسه میکند. برخی سیستمها در این کار بسیار حرفهای شدهاند. سیستم پیشنهادِ فیلم به مرور زمان طبع فیلم دیدنِ شما را عوض میکند و فهرست فیلمهای مورد علاقهتان را محدود و محدودتر میسازد. طوری میشود که دیگر بدون آنها حس میکنید نمیتوانید فیلم درستی را برای دیدن انتخاب کنید و مدام ترس دارید نکند فیلم بد و یا خارج از ژانر مورد علاقهتان را انتخاب کرده باشید. هوش مصنوعی به طور تدریجی با شما کاری میکند که دیگر قدرت انتخاب فیلم را از دست داده و بی اختیار منتظر بنشینید تا هر چه را هوش مصنوعی به شما پیشنهاد میکند تماشا نمایید.
همچنین جالب است بدانید که ما حتی نمی دانیم تا چه اندازه افسارمان دست این الگوریتمهاست. نمونهی فیلمیِ آن خیلی وحشتآور نیست؛ اما فقط یک لحظه به دخالت هوش مصنوعی در تبلیغات و اخبار فکر کنید.
- همبستگیهای غلط
یک همبستگی غلط زمانی رخ میدهد که چیزها -کاملاً مستقل از همدیگر- رویهای یکجور از خود نشان دهند. این امر میتواند به انسان این توهم را بدهد که آنها تا حدی با هم همبستگی و ارتباط معنادار دارند. برای مثال آیا میدانستید مصرف مارگارین (کرهی گیاهی) در آمریکا تا حد زیادی با نرخ طلاق در ایالت مین همبستگی دارد؟
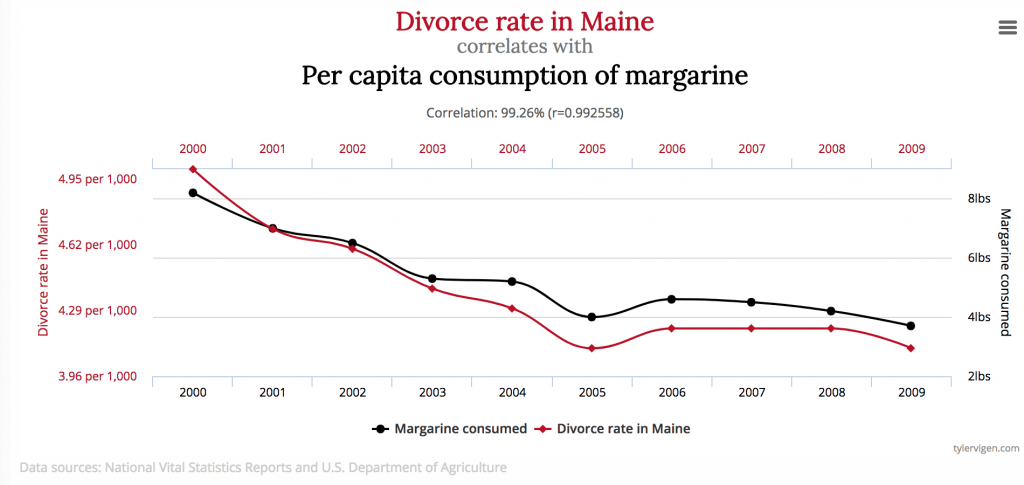
البته برخی -بنا بر تجارب شخصی و هوش انسانی- همواره فکر میکنند هر ارتباط مستقیمی بین این دو مسئله بعید و محال است. یک مدل ریاضی نمیتواند چنین دانشی داشته باشد- تنها کارش یادگیری و تعمیم دادههاست.
نمونهی بارز آن برنامهایست که بیماران را بنا بر درجهی نیازشان به کمک پزشکی تقسیمبندی کرد و در نهایت به این نتیجه رسید که بیمارانِ مبتلا به آسم که ذات الریه داشتند اوضاعشان به حادیِ بیماران ذاتالریه که آسم نداشتند نیست. این برنامه به دادهها نگاه میکرد و در نهایت نتیجه اش این بود که بیماران آسمی کمتر در خطر مرگ بودند و بنابراین نباید در اولویت قرارشان داد. در حقیقت دلیل پایین بودن نرخ مرگ بر اثر آسم این بود که این بیماران همیشه مراقبتهای فوری پزشکی دریافت میکردند (زیرا شرایطشان به حدی وخیم بود که ممکن بود هر آن بر اثر این بیماری جان خود را از دست دهند).
- حلقههای بازخورد
بازخوردها حتی از همبستگیهای کاذب نیز بدتر هستند. یک حلقهی بازخورد جایی است که در آن، تصمیمهای یک الگوریتم بر واقعیت تأثیر میگذارد که در عوض الگوریتم را متقاعد میسازد نتیجهگیریاش درست است. برای مثال، یک برنامهی جلوگیری از جرم در کالیفرنیا پیشنهاد داد که (بر اساس نرخ جرم) پلیس باید افسران بیشتری به مناطق آفریقایی-آمریکایی اعزام کند (تعداد جرم و جنایتهای ثبت و ضبطشده). اما وجود نیروهای بسیار در منطقه باعث شد شهروندان تعداد دفعات بیشتری گزارش جرم دهند (و اینگونه افسران مجبور بودند مدام به منطقه اعزام شوند).
- پایگاه دادهی مرجع "آلوده" یا "سمی"
پیامدهای یادگیریِ الگوریتم تا حد زیادی به پایگاه دادهی مرجع بستگی دارد که اساس یادگیری را شکل میدهد. با این حال، این دادهها ممکن است یا به طور تصادفی و یا تعمداً (که معمولاً در این مورد میگویند پایگاه اطلاعاتی مرجع سمی است) از سوی شخص بد و مخرب از آب دربیایند.
در ادامه نمونهای از مشکلات غیرعمد و تصادفی در بخش پایگاههای اطلاعاتی مرجع آوردهایم. اگر اطلاعاتی که برای بکارگیری یک الگوریتم -به عنوان نمونهی آموزشی- مورد استفاده قرار میگیرند از سوی شرکتی باشد که فعالیتهای نژادپرستانه انجام میدهد، این الگوریتم هم نژادپرستانه خواهد بود.
زمانی مایکروسافت به یک چتبات طریقهی چت با کاربران را در توییتر آموزش داد. و بعد کمتر از 24 ساعت مجبور شدند این پروژه را تمام کنند زیرا برخی کاربران به این ربات یاد داده بودند که مثلاً کتابِ نبرد من (نوشتهی هیتلر) را از بَر بخواند.
«تِی[5] تنها در عرض 24 ساعت از "آدمها خیلی خوبند" به یک نازیِ تمامعیار تبدیل شد و من خیلی به آیندهی هوش مصنوعیخوشبین نیستم»
_ گری geraldmellor) @) 24 مارس سال 2016
حال بیایید نمونهای از یک دادهی مسموم را در یادگیری ماشین مورد بررسی قرار دهیم. مدل ریاضیِ یک لابراتوارِ تحلیل ویروس کامپیوتری به طور متوسط روزانه 1 میلیون فایل را پردازش میکند؛ این کار هم میتواند خوب باشد و هم آسیبرسان.
یک هکر میتواند درست مشابه با کارکرد فایلهای صحیح، به تولید فایلهای مخرب ادامه دهد و آنها را به لابراتوار بفرستد. این عمل به تدریج مرز بین فایلهای مخرب و فایلهای خوب را از بین میبرد و کارایی مدل را پایین میآورد؛ شاید هم نهایتاً مثبت کاذب را مورد هدف خویش قرار دهد. از همین روست که لابراتوار کسپرسکی دارای مدل امنیتی چندلایه است و هیچگاه تماماً به یادگیری ماشین تکیه نمیکند. متخصصین آنتیویروس همیشه عملکرد ماشین را تحت نظارت قرار میدهند.
- فریب
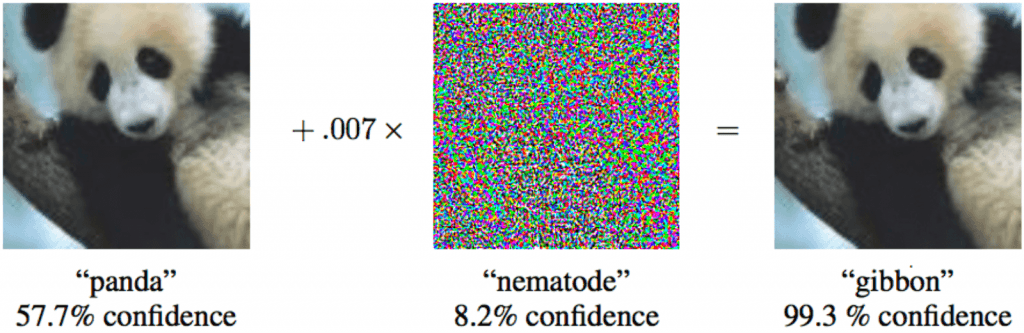
حتی یک مدل ریاضی که عملکرد خوبی دارد -همانی که تکیهاش بر دادههای خوب است- نیز باز میتواند فریب بخورد؛ تنها کافی است لِمَش را بداند. برای مثال، گروهی از محققین دریافتند چطور یک الگوریتم شناسایی چهره را با استفاده از عینکهای بخصوص -که کمترین میزان مداخله را در تصویر ایجاد میکنند- گول بزنند و نهایتاً کل نتیجه را تغییر دهند.

علاوه بر این، نیازی نیست برای کاهش مدل ریاضیِ یادگیری ماشین، این تغییرات بسیار فاحش و قابلملاحظه باشند- تغییرات جزئی که چشم انسان آنها را تشخیص نمیدهد کافی خواهد بود.

مادامیکه بشر از بسیاری از الگوریتمها هوشمندتر باشد، انسانها قادر خواهند بود به آنها کلک بزنند. فناوری یادگیری ماشینی را در آینده متصور شوید که چمدانی را در فروشگاه با اشعهی ایکس بازرسی میکند و به دنبال اسلحه است؛ یک تروریست حرفهای به سادگی خواهد توانست جسمی با قد و قوارهای مشابه را کنار اسلحه بگذارد و محموله را قایم کند.
چه کسی تقصیرکار است؟ و چاره چیست؟
در سال 2016، "گروه کار کلان داده" متعلق به ریاست جمهوری اوباما گزارشی منتشر کرد و در مورد "احتمال رمزگذاریِ تفاوتها در تصمیمهای اتوماتیک" هشدار داد. این گزارش همچنین حاوی درخواستی بود برای ساخت الگوریتمهایی که دنبال کردن چنین اصولی از اساس در طراحیشان نهادینه شده است.
البته گفتن این حرف آسانتر از عمل کردن به آن است.
اول از همه اینکه آزمایش و اصلاح مدل ریاضی یادگیری ماشین کار بسیار سختی است. ما برنامههای عادی را قدم به قدم ارزیابی میکنیم و میدانیم چطور آنها را آزمایش کنیم؛ اما وقتی پای یادگیری ماشین وسط است، همهچیز به سایز نمونهی یادگیری بستگی دارد.
دوم اینکه بهسختی میتوان تصمیمات الگوریتمهای یادگیری ماشین را درک نموده و توضیح داد. یک شبکهی عصبی، عاملهای مشترک بسیاری را در خود مرتب میکند تا نهایتاً به یک پاسخ درست برسد؛ اما چگونه؟ چطور میشود این جواب را تغییر داد؟
هیچ کس را نمیتوان سرزنش کرد؛ این ما هستیم که باید قوانین و قواعد اخلاقی جدیدی برای علم رباتیک تعریف کنیم. در ماه می 2018، کشور آلمان اولین گامهای خود را در این راستا برداشت و برای خودروهای خودگردان قوانین اخلاقی جدیدی وضع کرد.
بدیهی است که هر چه پیش میرویم، بیشتر و بیشتر به یادگیری ماشین وابسته میشویم، تنها به این دلیل که این فرآیند کارها را خیلی بهتر از برخی از ما انسانها مدیریت میکند. بنابراین، باید این نواقص و مشکلات را همیشه مد نظر داشت و تمامی احتمالات را در مرحلهی ساخت در نظر گرفت. همچنین میبایست به یاد داشت اگر روند کارکرد الگوریتمی در آستانهی انحراف است، آن را با دقت تمام مورد بررسی و نظارت قرار داد.
[1] Machine learning، یکی از شاخههای وسیع و پرکاربرد هوش مصنوعی است و به تنظیم و اکتشاف شیوهها و الگوریتمهایی میپردازد که بر اساس آنها رایانهها و سامانهها توانایی تعلٌم و یادگیری پیدا میکنند.
[2] Go، یکی از قدیمیترین بازیهای تختهای تاریخ بشری است. این بازی که به صورت دونفره انجام میشود، علیرغم قوانین سادهای که دارد راهبردهای (استراتژیهای) پیچیدهای را میطلبد.
[3] (Fusion power) قدرتی است که توسط عملیاتهای همجوشی هستهای تولید میشود.در این واکنش، دو هسته اتمی با یکدیگر ادغام میشوند برای تولید یک هستهٔ سنگین تر و انرژی زیادی از آن آزاد میشود. قدرت همجوشی در حال حاضر در فیزیک پلاسما مورد بررسی است.
[4] شامل افرادی است که گرایش جنسی و رفتار جنسی متفاوت از دگرجنسگرایی دارند که شامل همجنسگرایی مردانه، همجنسگرایی زنانه، دوجنسگرایی و دگرجنس گونه گان میباشد.
[5] نام چتبات مایکروسافت.
منبع: کسپرسکی آنلاین (ایدکو)
کسپرسکی اسم یکی از بزرگترین شرکتهای امنیتی و سازنده آنتی ویروس است که برخی از کاربران اشتباهاً این شرکت و محصولات آنتی ویروس آن را با عناوینی نظیر کسپرسکای،کاسپرسکی، کسپراسکی، کسپراسکای، و یا کاسپراسکای نیز میشناسد. همچنین لازم به ذکر است مدیرعامل این شرکت نیز یوجین کسپرسکي نام دارد.